Retail & E-Commerce Data Annotation: Guidelines and Best Practices

TL;DR
- Retail and e-commerce data annotation labels product images, text, and behavioral data to train AI for search, recommendations, and catalog management.
- Common annotation types include image classification, attribute tagging, sentiment analysis, OCR, and search relevance labeling.
- Annotation quality directly determines how well AI-powered search, discovery, and personalization perform in production.
- Effective annotation projects need versioned guidelines, clear taxonomy, QC checkpoints, and calibrated annotators from day one.
- Enterprise teams use multi-layer QA (Maker-Checker, Majority Vote, golden tasks) to keep labels consistent across categories and seasons.
You spend months training a visual search model. It launches. Customers search “floral midi dress” and get results for floral rugs, formal dresses, and one item that hasn’t been in stock since last spring.
The model isn’t broken. The labels are. Someone tagged “print: floral” on the rug category. Another annotator used “length: midi” for anything knee-length. A third left dress silhouette blank on 40% of the catalog. The model just learned from all of it.
This is what happens when retail and e-commerce data annotation gets treated as a clerical task rather than a precision operation. The decisions made in the annotation pipeline, what to label, how to define edge cases, how to catch drift, show up directly in product discovery accuracy, recommendation quality, and return rates.
This guide covers the annotation types, project guidelines, and QA frameworks that enterprise teams actually use. Let’s get into it.
What is Data Annotation in Retail & E-Commerce?
At its core, retail and e-commerce data annotation is the process of adding structured labels to product images, catalog text, customer reviews, user behavior signals, and inventory data so machine learning models can learn from them. Without these labels, raw data tells a model nothing. With them, it can classify a product, match a search query, detect a counterfeit listing, or predict what a customer will buy next.
The scope of annotation in this space is wider than most teams initially expect. It’s not just “tag the category.” A well-annotated product dataset captures the item’s type, material, color, condition, occasion suitability, dominant style, and relationship to similar items. That depth is what separates a recommendation engine that converts from one that annoys.
What makes retail and e-commerce annotation distinct from general-purpose labeling is catalog scale and seasonal variability. A fashion retailer might onboard 50,000 new SKUs per quarter. Each one needs a consistent taxonomy applied before it goes live. If you miss the window and the item surfaces in wrong categories, it gets buried in search, or pairs badly in recommendations. The stakes are commercial, not just technical. Understanding what data labeling really means in this context is the starting point for building annotation pipelines that hold up at that scale.
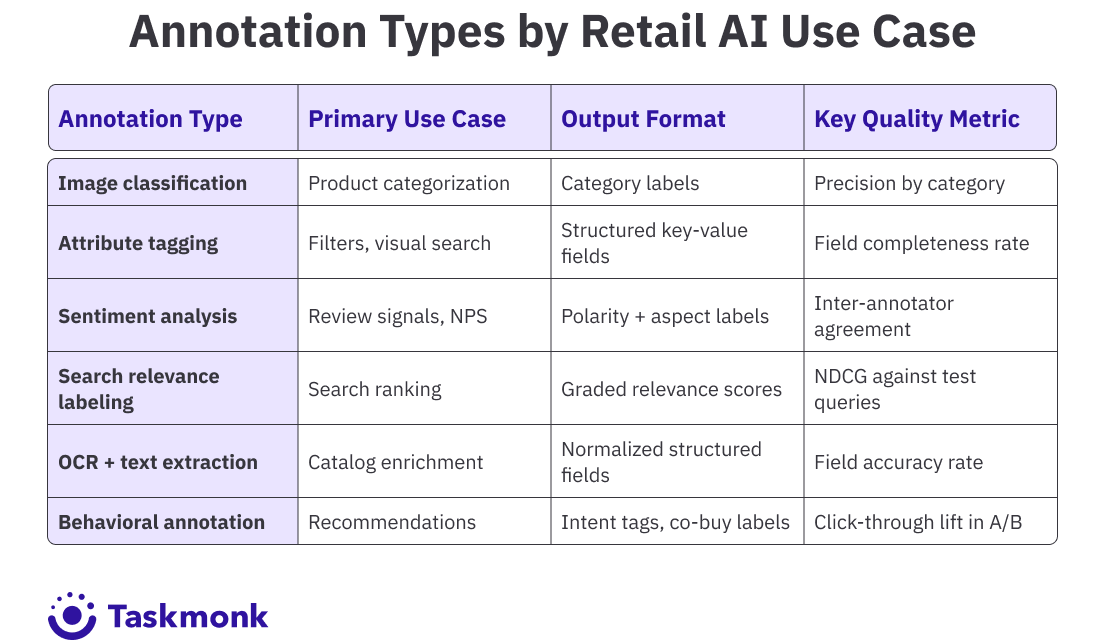
Types of Data Annotation Used in Retail and E-Commerce
The annotation types you need depend on which AI use cases you’re building for. Most enterprise retail teams are running several in parallel.
Image Annotation for Product Catalogs
Product image annotation covers bounding boxes around items in lifestyle shots, polygon segmentation for background removal, keypoint labeling for fit visualization, and classification tags for categories and visual attributes. It’s the backbone of visual search, similar-item recommendations, and automated catalog QA that flags images outside brand spec.
For fashion specifically, this includes labelling attributes like neckline, fit, sleeve length, closure type, and dominant pattern because shoppers filter on all of these. A model that can’t distinguish a crew neck from a V-neck from a band collar will serve irrelevant results when customers use those filters.
Pro tip: Don’t treat category and attribute labeling as one pass. Category labels are coarser and can tolerate more ambiguity. Attribute labels (color, material, style) require tighter consensus rules because they feed search filters directly. Run them in separate workflows with separate quality targets.
Product image annotation for e-commerce requires category-specific checklists rather than generic labeling templates. What matters for electronics differs from what matters for apparel or furniture.
Text Annotation for Catalogs and Reviews
Text annotation in retail includes named entity recognition to extract product specifications from unstructured descriptions, sentiment analysis on customer reviews and Q&A threads, search relevance labeling to score query-product pairs, and title normalization to create consistent, importable catalog fields.
This work feeds the systems customers interact with most: site search, filters, chatbots, and personalized email. Text annotation for retail is particularly demanding because product language is inconsistent across sellers, markets, and categories. One seller writes “cobalt blue,” another writes “navy,” another writes “#123456.” Someone has to define the mapping, and then someone has to enforce it across millions of listings.
Behavioral Data Annotation
User behavior signals (clicks, add-to-cart actions, dwell time, purchase sequences) need annotation to become training data for recommendation models. This includes labeling query intent (navigational vs. exploratory vs. transactional), tagging co-view and co-buy relationships, and scoring session paths to distinguish genuine browsing from bot traffic.
This is less visible than image or text annotation but often has more direct impact on conversion metrics. A recommendation model trained on poorly labeled behavioral data will surface the wrong signals and optimize for the wrong outcomes.
Document and OCR Annotation
Retail operations also rely on document annotation for supplier onboarding (extracting specs from PDFs and data sheets), invoice processing, returns classification, and compliance document review. OCR annotation corrects errors in extracted text and labels document fields so downstream automation can act on them reliably.
Why Annotation Quality Drives AI Performance in Retail
The relationship between annotation quality and model performance is direct and unforgiving in retail AI. A model trained on inconsistent product labels doesn’t just perform poorly on a benchmark. It surfaces wrong products in search, recommends items customers can’t find in their size, and drives up returns on items that didn’t match the catalog description.
Annotation errors definitely compound over time. If 8% of your attribute labels are wrong during training, your model doesn’t just make errors 8% of the time. It learns the wrong patterns and generalizes them. A model that consistently saw “maxi” applied to anything below the knee will confidently mislabel at scale once it ships.
The second problem is label drift. In retail, catalogs change every season. New categories get added. Attribute definitions evolve. If annotation guidelines aren’t versioned and distributed, annotators working three months apart will apply different rules to equivalent products. The model sees noise it can’t distinguish from signal.
Quality also affects the speed of the entire AI pipeline. Teams that front-load quality control, catching errors in the annotation stage rather than after training, ship faster and rework less. For a deep look at how enterprise annotation teams build quality systems, the guide to data labeling quality covers the metrics and review structures that actually work at scale.
Best Practices for Retail & E-Commerce Data Annotation
The difference between annotation pipelines that hold up and ones that fail at scale usually comes down to a few structural decisions made early.
Taxonomy before scale: Define your category tree and attribute schema before you annotate the first batch. Retrofitting taxonomy onto a labeled dataset is expensive and error-prone. This means agreeing on what counts as a distinct category (is “blazer” a type of “jacket” or a sibling category?), what attributes apply per category, and how edge cases get resolved. Write it down. Version it.
Annotator calibration on your data, not generic training: Most annotation errors in retail aren’t caused by carelessness. They’re caused by ambiguity the guidelines didn’t anticipate. An annotator sees a denim jacket with a sherpa lining and isn’t sure whether to apply “denim” or “sherpa” as the material. Calibration sessions using actual catalog examples, not hypothetical ones, catch these gaps before they become a pattern.
Separation of category and attribute workflows: Category labeling and attribute tagging have different accuracy profiles and different downstream effects. Running them in separate workflows with separate QC thresholds lets you apply the right level of rigor per task type without bottlenecking everything.
Feedback loops between annotation and model performance: When a deployed model starts making consistent errors on a class of products, trace it back to the training labels. What did the annotators see? What did the guidelines say? This loop is how annotation specs improve over time.
Pro tip: Build “golden task” sets for every product category, not just for the full annotation pool. A golden set for dresses, a separate one for outerwear, another for accessories. Category-specific golden tasks catch attribute drift that generic quality checks miss entirely.
Guidelines for Setting Up an Effective Annotation Project
Getting a retail annotation project to a stable production state requires more than writing guidelines and sending tasks to annotators. The setup decisions determine whether you spend the next six months reworking batches or shipping clean data.
Define the Ontology Before Writing Guidelines
An ontology is your full taxonomy: categories, subcategories, attribute names, attribute values, and the rules for how they relate to each other. In retail, this is often the hardest part of the project because it requires decisions the business hasn’t formally made. Does “teal” map to “blue” or “green”? Is a “maxi skirt” a separate subcategory or an attribute value of “skirt”?
These aren’t annotation questions. They’re product data questions that annotation makes visible. Get the category and merchandising teams to sign off on the ontology before any labeling starts. Annotation guidelines built on a shaky ontology will need to be rewritten.
Write Guidelines with Edge Cases as the Focus
Most annotation guidelines spend too much time describing the obvious case and too little describing the boundary cases. Any annotator can tag a plain white T-shirt. The guidelines need to address what happens when the T-shirt has a small graphic, is marketed as a “graphic tee,” and the graphic covers less than 10% of the front surface. Write those rules explicitly.
For each attribute, include: the definition, at least two positive examples with images, at least one negative example, and the edge case rule. Guidelines without visual examples fail faster than those with them.
Set Throughput Expectations That Match Quality Requirements
Attribute tagging for a fashion catalog at the quality level that feeds live search filters takes longer per item than basic category classification. If your throughput targets assume category-classification speed for attribute-level work, annotators will cut corners to hit the numbers. Set separate throughput targets per task type and communicate them clearly.
Pro tip: Pilot every new annotation spec on 100-200 items before opening the full batch. Review the pilot output with the team that will use the labels. You’ll catch spec gaps that only become visible in practice.
Quality Assurance Frameworks for Retail Annotation
QA in retail annotation isn’t a single review at the end. It’s a system of checkpoints that catch errors at the source, monitor drift over time, and surface signal for continuous improvement.
Maker-Checker pairs each annotation task with a separate reviewer who checks the label before it passes. It’s the default for high-stakes work: attribute labels that feed live search, sentiment labels that feed brand monitoring, relevance labels that feed ranking. The separation of labeler and reviewer roles creates accountability and catches individual errors before they compound.
Majority Vote sends the same task to multiple annotators and accepts the label that appears most often. It works well for tasks with clear ground truth (category classification, binary relevance judgments) and provides a built-in IAA (inter-annotator agreement) signal at no additional cost.
Golden Tasks are items with known correct labels, embedded in the annotation queue without annotators knowing. They measure accuracy per annotator over time and flag drift before it affects the full dataset. In retail, golden tasks should be refreshed every quarter, or whenever the product taxonomy changes, to stay representative.
IAA (inter-annotator agreement) is the metric that ties these methods together. For attribute-level tasks in fashion and home goods, most enterprise teams target IAA above 85% as a working threshold. Below that, the guidelines are ambiguous and need revision, not just more training.
For multi-vendor catalogs, add a consistency check layer: compare labels for the same product appearing under different seller listings. Divergence signals either a taxonomy gap or annotator inconsistency.
Common Challenges in Retail Data Annotation (and How to Solve Them)
Ambiguous product descriptions: A supplier writes “cream,” another writes “off-white,” another writes “ivory.” All three might describe the same color, or they might not. The solution isn’t to train annotators to make that call in isolation. It’s to build a color normalization map, a lookup table that maps raw supplier values to your canonical taxonomy, and keep it updated as new suppliers onboard.
Catalog scale vs. turnaround time: A seasonal fashion retailer can’t wait two weeks for labels on new arrivals. Enterprise teams solve this through pre-labeling: a model trained on existing labeled data generates candidate labels for new items, and annotators review and correct rather than labeling from scratch. Pre-labeling can cut annotation time substantially on well-established categories. It won’t work well on genuinely new categories where no labeled precedent exists, so identify those early and plan for fully manual annotation there.
Annotator specialization at scale. A generalist annotator who labels everything from grocery items to luxury handbags will do both poorly. Enterprise teams route tasks by domain: annotators who work on fashion understand fit and construction; annotators who work on electronics understand specs and compatibility. This isn’t just a quality decision. It’s a throughput decision. Domain-matched annotators work faster and flag fewer edge cases.
Label drift over seasons. What “oversized” means in a product attribute can shift between spring and fall collections. If you don’t revisit and recalibrate guidelines seasonally, drift accumulates silently. Set a calendar review for every taxonomy definition tied to trend-sensitive attributes.
Pro tip: Log every annotator question that required a supervisor decision. These aren’t noise. They’re your spec gaps. A well-maintained FAQ document built from real annotator questions prevents the same edge case from being resolved inconsistently across batches.
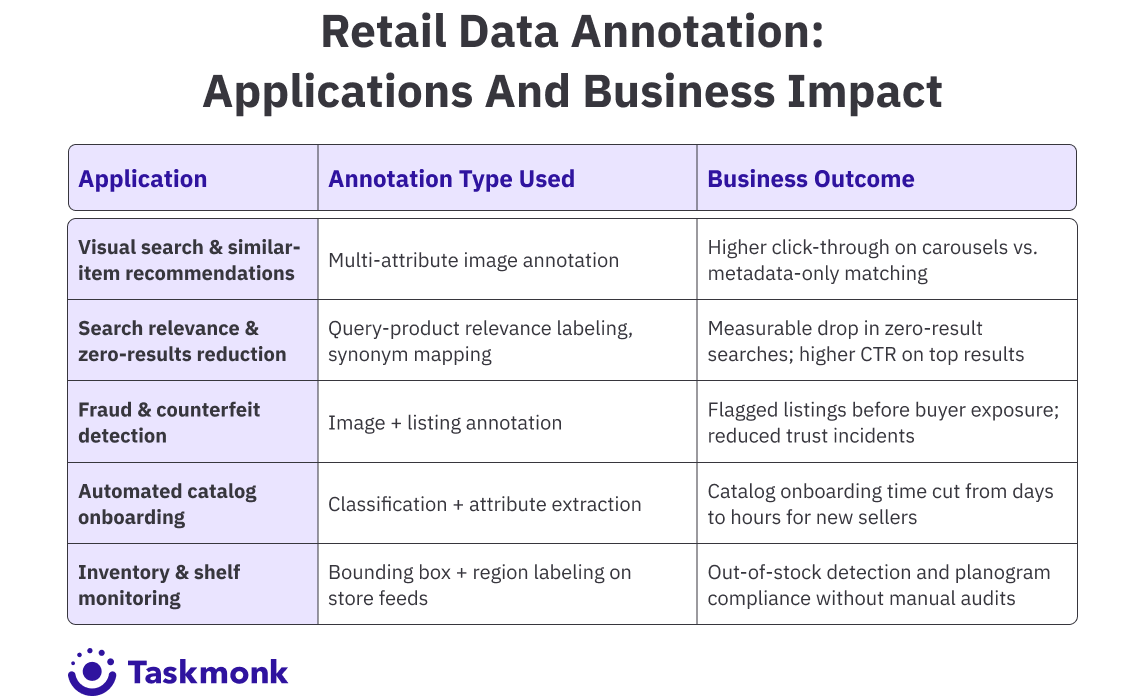
Real-World Applications of Retail Data Annotation
Annotation work shows up in the AI features customers interact with daily. Here’s where it has the most direct commercial impact.
How TaskMonk Handles Retail & E-Commerce Data Annotation
Most annotation vendors treat a retail project as a labeling job. TaskMonk treats it as a catalog operations problem. That framing changes how the work gets scoped, staffed, and reviewed.
Catalog operations require annotation that’s consistent across categories, consistent across seasons, and consistent across the vendors or annotators working on it simultaneously. That consistency doesn’t come from good intentions. It comes from architecture.
Catalog-first workflows: TaskMonk’s e-commerce annotation pipelines are built around taxonomy mapping, attribute normalization, and catalog enrichment built from our extensive retail & fashion project experience rather than generic labeling templates. Task UIs are configured per category: apparel workflows surface the right attribute fields for apparel, electronics workflows surface spec fields, and the two never bleed into each other. This reduces annotator errors and speeds throughput simultaneously.
Multi-layer QC without engineering overhead. TaskMonk’s no-code platform lets teams configure Maker-Checker, Majority Vote, and golden task workflows per project without writing code. Quality rules (field completeness checks, value validation against the taxonomy, sampling triggers for low-confidence items) run automatically. Teams see real-time dashboards rather than discovering quality problems after the batch closes.
Affinity-based annotator routing. TaskMonk routes tasks to annotators based on domain match, not just availability. Fashion catalog work goes to annotators calibrated on fashion data. Electronics specs go to annotators with electronics domain experience. This reduces edge case interruptions and produces tighter IAA scores.
Image and text in one workflow. Most annotation platforms treat product images and product text as separate workstreams requiring separate tooling. TaskMonk handles both in one integrated workflow, so the same product gets its image labeled and its description normalized in a single pass. This matters for teams building multimodal search or recommendation models that need visual and textual signals from the same item.
TaskMonk has supported large-scale retail and e-commerce annotation programs at Walmart, Flipkart, and Myntra, and has processed 480M+ tasks and delivered 6M+ hours of annotation work across product data, images, and reviews spanning fashion to grocery to electronics. More than 10 Fortune 500 companies rely on TaskMonk for accurate, scalable annotation. The platform holds a 4.6/5 rating on G2, with reviews consistently citing quality control and responsive support.
If you want to see how it works against your catalog data, book a demo with the TaskMonk e-commerce team. They’ll scope a workflow for your category set and return labeled samples with a QA report within 48 hours.
Conclusion
The gap between an AI feature that converts and one that frustrates is, more often than not, a data gap. Retailers who treat annotation as a commodity purchase, lowest cost per label, fastest turnaround, discover it at the worst moment: after a model ships and recommendation quality drops, or after visual search launches and customers stop using it.
The teams that get this right think about annotation the way they think about their catalog: as an ongoing operational system that needs ownership, governance, and regular review. They don’t just run projects. They maintain standards.
Retail and e-commerce data annotation isn’t a one-time investment. It’s the infrastructure underneath every AI feature your customers interact with. Build it like it matters, because it does.


